linux_kernel_pwn初探
前置知识
一、内核
操作系统(Operation System)本质上就是一个管理着计算机硬件和软件资源并为计算机程序提供公共服务的系统软件,其主要功能就是调度系统资源、控制IO设备等等。Linux系统整体结构如下。
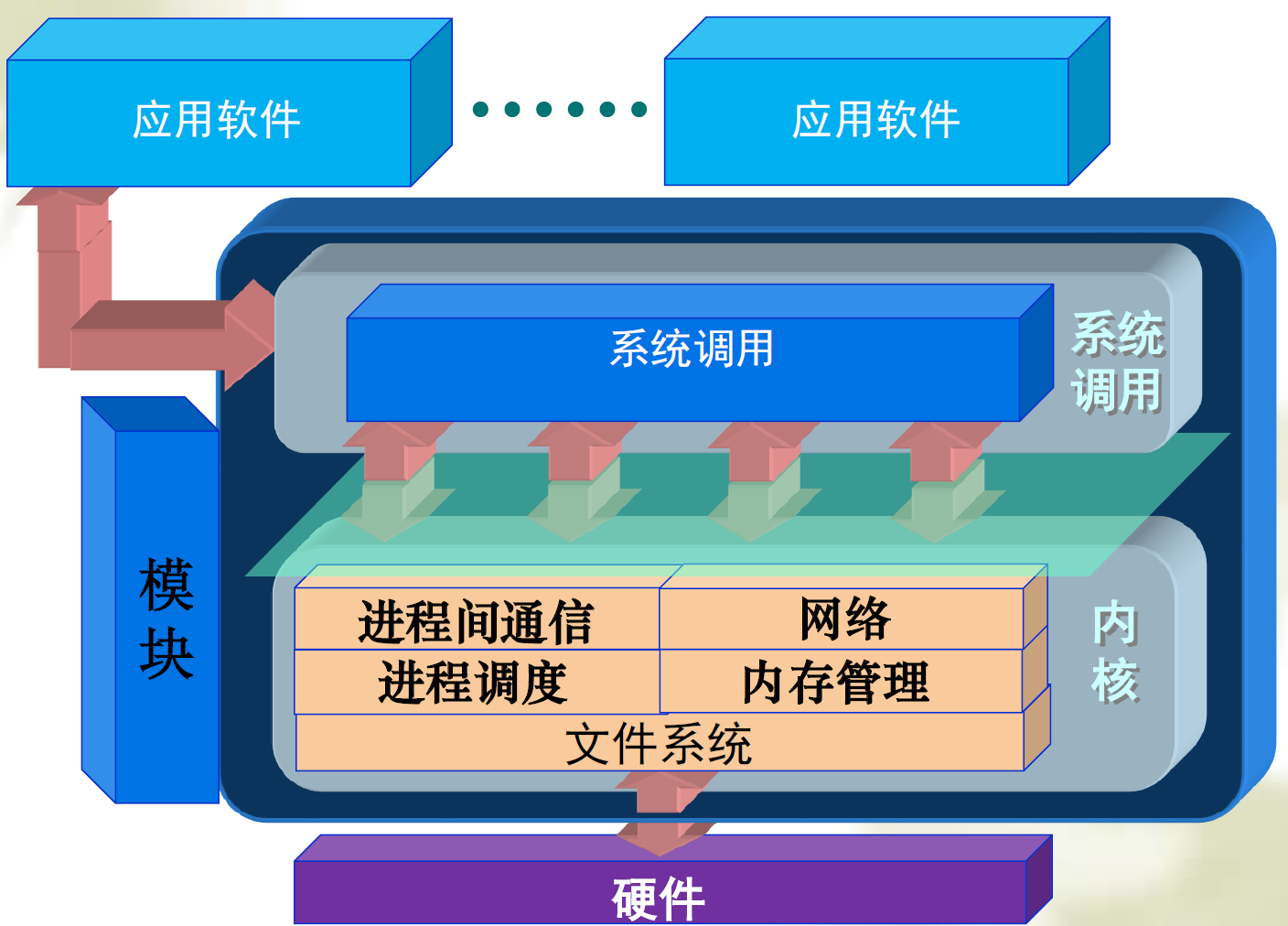
内核 (kernel)也是一个程序,用来管理软件发出的数据 I/O 要求,将这些要求转义为指令,交给 CPU 和计算机中的其他组件处理,kernel 是现代操作系统最基本的部分。
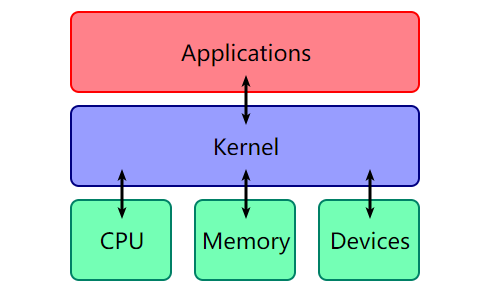
kernel 最主要的功能有两点:
- 控制并与硬件进行交互
- 提供 application 能运行的环境
包括 I/O,权限控制,系统调用,进程管理,内存管理等多项功能都可以归结到上边两点中。
需要注意的是,kernel 的 crash 通常会引起重启。
二、分级保护域
intel CPU 将 CPU 的特权级别分为 4 个级别:Ring 0, Ring 1, Ring 2, Ring 3,权限等级以此降低。
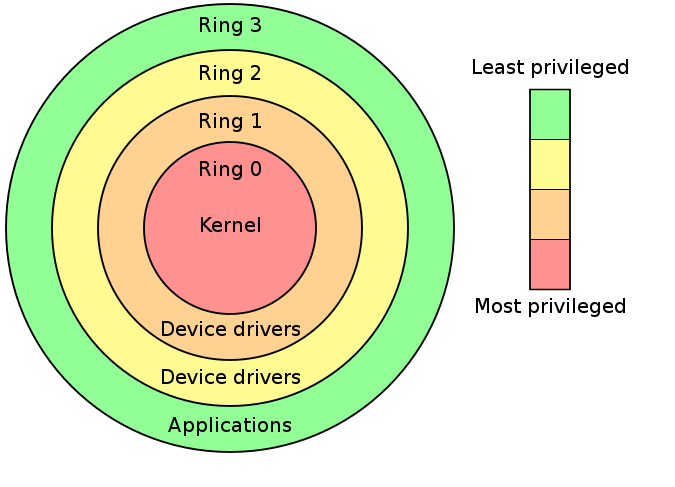
Ring0 只给 OS 使用,Ring 3 所有程序都可以使用,内层 Ring 可以随便使用外层 Ring 的资源。
大多数的现代操作系统只使用了 Ring 0 和 Ring 3,其中 kernel 运行在 ring0,用户态程序运行在 ring3
使用 Ring Model 是为了提升系统安全性,例如某个间谍软件作为一个在 Ring 3 运行的用户程序,在不通知用户的时候打开摄像头会被阻止,因为访问硬件需要使用 being 驱动程序保留的 Ring 1 的方法。
用户态和内核态
当进程运行在内核空间时就处于内核态,运行在用户空间时则处于用户态
在内核态下,进程运行在内核地址空间中,此时 CPU 可以执行任何指令
在用户态下,进程运行在用户地址空间中,此时CPU所执行的指令是受限的
进程运行态切换
应用程式运行时总会经历无数次的用户态与内核态之间的转换,这是因为用户进程往往需要使用内核所提供的各种功能(如IO等),此时就需要陷入(trap)内核,待完成之后再“着陆”回用户态。
用户态 -> 内核态
当发生系统调用,产生异常,外设产生中断等事件时,会发生用户态到内核态的切换,具体的过程为:
- 通过
swapgs切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换,目的是保存 GS 值,同时将该位置的值作为内核执行时的 GS 值使用。 - 将当前栈顶(用户空间栈顶)记录在 CPU 独占变量区域里,将 CPU 独占区域里记录的内核栈顶放入 rsp/esp。
- 通过 push 保存各寄存器值,具体的 代码 如下:
1 | |
- 通过汇编指令判断是否为
x32_abi。 - 通过系统调用号,跳到全局变量
sys_call_table(保存着系统调用的函数指针)相应位置继续执行系统调用。
内核态 -> 用户态
退出时,流程如下:
- 通过
swapgs恢复 GS 值 - 通过
sysretq或者iretq恢复到用户控件继续执行。如果使用iretq还需要给出用户空间的一些信息(CS, eflags/rflags, esp/rsp 等)
三、系统调用
系统调用,指的是用户空间的程序向操作系统内核请求需要更高权限的服务,比如 IO 操作或者进程间通信。系统调用提供用户程序与操作系统间的接口,部分库函数(如 scanf,puts 等 IO 相关的函数实际上是对系统调用的封装(read 和 write))。
在 /usr/include/x86_64-linux-gnu/asm/unistd_64.h 和 /usr/include/x86_64-linux-gnu/asm/unistd_32.h 分别可以查看 64 位和 32 位的系统调用号。
使用系统调用时会陷入内核态,接着由操作系统完成请求
系统调用本质上与一般的C库函数没有区别,不同的是系统调用位于内核空间,以内核态运行
进入系统调用
Linux 下进入系统调用有两种主要的方式:
- 32位:执行
int 0x80汇编指令(80号中断) - 64位:执行
syscall汇编指令 / 执行sysenter汇编指令(only intel)
接下来就是由用户态进入到内核态的流程
Linux下的系统调用以eax/rax寄存器作为系统调用号,参数传递约束如下:
- 32 位:
ebx、ecx、edx、esi、edi、ebp作为第一个参数、第二个参数…进行参数传递 - 64 位:
rdi、rsi、rdx、rcx、r8、r9作为第一个参数、第二个参数…进行参数传递
退出系统调用
同样地,内核执行完系统调用后退出系统调用也有对应的两种方式:
- 执行
iret汇编指令 - 执行
sysret汇编指令 / 执行sysexit汇编指令(only Intel)
接下来就是由内核态回退至用户态的流程
四、进程权限管理
进程描述符
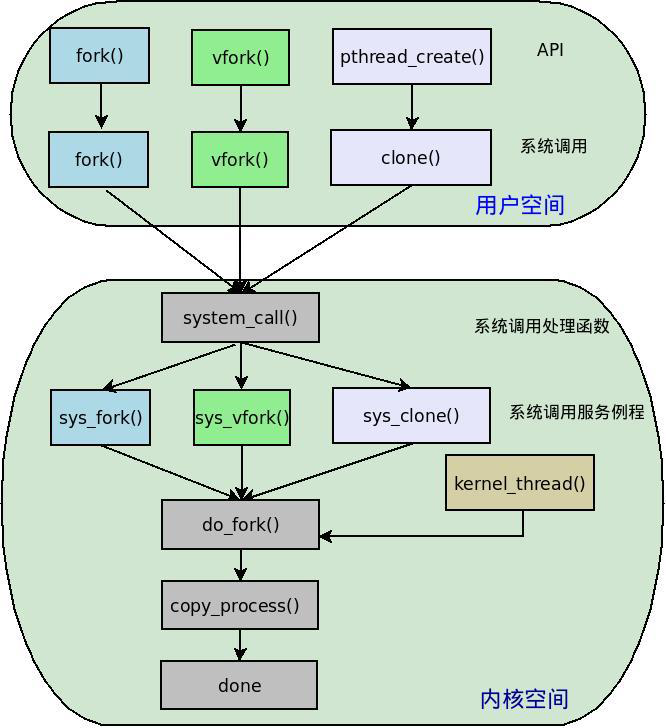
在内核中使用结构体 task_struct 表示一个进程,该结构体定义于内核源码include/linux/sched.h中。
1 | |
进程,线程和内核线程都是使用这个task_struct结构体,在内核中最终都会调用do_fork()函数。
进程权限凭证
之前提到 kernel 记录了进程的权限,更具体的,是用 cred 结构体记录的,每个进程中都有一个 cred 结构,这个结构保存了该进程的权限等信息(uid,gid 等),如果能修改某个进程的 cred,那么也就修改了这个进程的权限。该结构定义在include/linux/cred.h中
1 | |
提权
在内核空间有如下两个函数,都位于kernel/cred.c中:
struct cred* prepare_kernel_cred(struct task_struct* daemon):该函数用以拷贝一个进程的cred结构体,并返回一个新的cred结构体,需要注意的是daemon参数应为有效的进程描述符地址或NULLint commit_creds(struct cred *new):该函数用以将一个新的cred结构体应用到进程
查看prepare_kernel_cred()函数源码。
1 | |
在prepare_kernel_cred()函数中,若传入的参数为NULL,则会缺省使用init进程的cred作为模板进行拷贝,即可以直接获得一个标识着root权限的cred结构体
那么我们不难想到,只要我们能够在内核空间执行commit_creds(prepare_kernel_cred(NULL)),那么就能够将进程的权限提升到root,再运行一个system(“/bin/sh”)就能拿到root的shell了。
五、可装载内核模块(LKM)
可加载核心模块 (或直接称为内核模块) 就像运行在内核空间的可执行程序,包括:
- 驱动程序(Device drivers)
- 设备驱动
- 文件系统驱动
- …
- 内核扩展模块 (modules)
LKMs 的文件格式和用户态的可执行程序相同,Linux 下为 ELF,Windows 下为 exe/dll,mac 下为 MACH-O,因此我们可以用 IDA 等工具来分析内核模块。
模块可以被单独编译,但不能单独运行。它在运行时被链接到内核作为内核的一部分在内核空间运行,这与运行在用户控件的进程不同。
模块通常用来实现一种文件系统、一个驱动程序或者其他内核上层的功能。
Linux 内核之所以提供模块机制,是因为它本身是一个单内核 (monolithic kernel)。单内核的优点是效率高,因为所有的内容都集合在一起,但缺点是可扩展性和可维护性相对较差,模块机制就是为了弥补这一缺陷。
模块的编译需要用到Makefile,通常与LKM相关的命令有以下三个:
lsmod:列出现有的LKMsinsmod:装载新的LKM(需要root)rmmod:从内核中移除LKM(需要root)
六、保护机制
跟用户程序类似,内核也会有各种各样的保护机制
KASLR
KASLR即内核空间地址随机化(kernel address space layout randomize),与用户态程序的ASLR相类似——在内核镜像映射到实际的地址空间时加上一个偏移值,但是内核内部的相对偏移其实还是不变的
在未开启KASLR保护机制时,内核的基址为0xffffffff81000000
像用户空间的绕过手法一样,可以通过leak memory来bypass
smep
SMEP即管理模式执行保护(Supervisor Mode Execution Prevention),用以阻止内核空间直接执行用户空间的数据。CR4寄存器的第20位标志着是否开启这个保护。

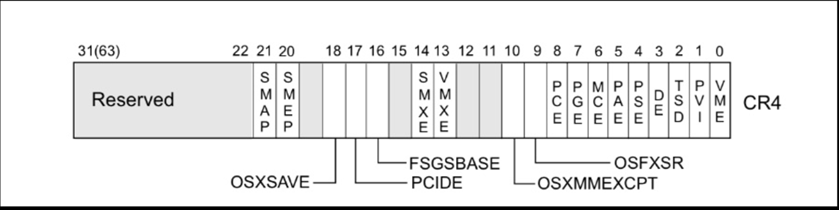
绕过方法:
- kernel ROP
- 修改addr_limit,set_fs(-1)(addr_limit用于限制用户态程序能访问的地址的最大值,通过set_fs可以改变thread_info->addr_limit的大小,如果把它修改成
0xffffffffffffffff,我们就可以读写整个内存空间了 包括 内核空间) - ret2dir,在设计中,为了使隔离的数据进行交换时具有更高的性能,隐性地址共享始终存在(VDSO & VSYSCALL),用户态进程与内核共享同一块物理内存,因此通过隐性内存共享可以完整的绕过软件和硬件的隔离保护,这种攻击方式被称之为
ret2dir(return-to-direct-mapped memory )
smap
SMAP即管理模式访问保护(Supervisor Mode Access Prevention),用以阻止内核空间直接访问用户空间的数据。CR4寄存器的第21位标志着是否开启这个保护。

绕过方法(较为苛刻):
- ret2dir
- ksma
- modprobe_path
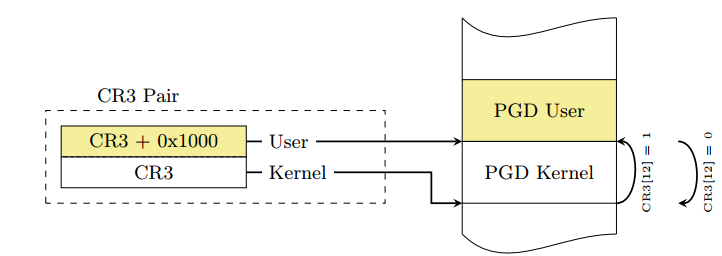
KPTI
KPTI即内核页表隔离(Kernel page-table isolation),内核空间与用户空间分别使用两组不同的页表集,这对于内核的内存管理产生了根本性的变化
环境搭建
这里全程以CISCN2017 - babydriver的环境搭建作为演示
一、编译内核
首先到linux内核的官网下载一份内核源代码并解压:
我下载的4.4.72的内核版本
解压
1 | |
安装一些环境依赖
1 | |
这些依赖并不一定全部概况完了,在编译的过程中可能在报错信息中还要提示你安装一些依赖,具体根据报错提示再进行安装就可以
然后进入解压目录
1 | |
一般默认就可以直接退出保存,运行如下命令开始编译,生成内核镜像(可以nproc查看本机CPU核数)
1 | |
完成之后有如下信息

在当前目录下提取到vmlinux,为编译出来的原始内核文件
1 | |
在当前目录下的arch/x86/boot/目录下提取到bzImage,为压缩后的内核文件,适用于大内核
1 | |
二、编译busybox构建文件系统
BusyBox 是一个集成了三百多个最常用Linux命令和工具的软件,包含了例如ls、cat和echo等一些简单的工具
在busybox.net下载自己想要的版本,这里选用busybox-1.33.0.tar.bz2这个版本
1 | |
注意为了避免不必要的麻烦,这个选择静态编译
Setting -> Build Options -> Build static binary (no shared libs)

保存后直接编译
1 | |
编译完make install后,在busybox源代码的根目录下会有一个 _install目录下会存放好编译后的文件

接下来一些初始化操作
1 | |
配置etc/inttab,写入如下内容
1 | |
在上面的文件中指定了系统初始化脚本,因此接下来配置etc/init.d/rcS,写入如下内容
1 | |
主要是配置各种目录的挂载
也可以在根目录下创建init文件,写入如下内容:
1 | |
最后加上可执行权限
1 | |
打包脚本,把需要加载的驱动放在同级目录
pack.sh
1 | |
比赛给的init脚本如下 ,其默认使用insmod加载了名为babydriver.ko
1 | |
三、qemu运行内核
为了方便,直接把启动命令存为文件
start.sh
1 | |
部分参数说明如下:
-m:虚拟机内存大小-kernel:内存镜像路径-initrd:文件系统路径-append:附加参数选项
nokalsr:关闭内核地址随机化,方便我们进行调试rdinit:指定初始启动进程,/sbin/init进程会默认以/etc/init.d/rcS作为启动脚本loglevel=3&quiet:不输出logconsole=ttyS0:指定终端为/dev/ttyS0,这样一启动就能进入终端界面
-monitor:将监视器重定向到主机设备/dev/null,这里重定向至null主要是防止CTF中被人给偷了qemu拿flag-cpu:设置CPU安全选项,在这里开启了smep保护-s:相当于-gdb tcp::1234的简写(也可以直接这么写),后续我们可以通过gdb连接本地端口进行调试
gdb调试
附上gdb调试脚本
1 | |
reference
https://arttnba3.cn/2021/02/21/NOTE-0X02-LINUX-KERNEL-PWN-PART-I/
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!